
Am 17. September 2015 hielt Theresa Liebl vor der Regionalgruppe Berlin den Vortrag mit dem Titel „Sprachverständlichkeit im Fernsehen“. Dieses Thema war so recht nach dem „Geschmack“ unseres Regionalleiters Wilhelm Sommerhäuser, der schon seit langem immer wieder über den schlechten Fernsehton schimpft, der heute allgemein seines Erachtens weit schlechter sei als früher. Als ehemaliger Technischer Direktor des SFB hat er auch die Ursachen klar erkannt und sie deshalb vor dem Referat nochmals deutlich benannt, nämlich
- schlechtes Sprechen der Schauspieler,
- mangelhafte Tonaufnahme (zum Teil situationsbedingt),
- aggressive Musikuntermalung,
- laute Umweltgeräusche,
- Voice over Voice.

Die Referentin, Theresa Liebl, IRT (Bild rechts) konnte das sogar im Laufe ihres Referats mit Argumenten bestätigen. Allerdings kann man gegen unsauberes Sprechen, zumal häufig zu schnell und mit Umgebungsgeräuschen „verunreinigt“, hinterher technisch kaum noch etwas machen, da hätte schon bei der Produktion das künstlerische Personal stärker darauf achten müssen. Und so lagen ihre Themen dann auch mehr bei Untersuchungen zur Sprachverständlichkeit und bei der Entwicklung eines Tools, um den Ton für Hörgeschädigte über HbbTV 2.0 verbessern zu können. Sie begann ihr Referat aber mit Untersuchungen und Empfehlungen bei Voice-over-Voice-Situationen. Sie waren auch Teil ihrer Bachelorarbeit am Institut für Rundfunktechnik, München. Mit dieser Arbeit gehörte sie zu einer der drei diesjährigen Preisträgerinnen des ARD/ZDF Förderpreises „Frauen + Medientechnologie“, der ihr auf der Internationalen Funkausstellung überreicht wurde.
[caption align] Auditorium beim Vortrag im rbb[/caption]
Auditorium beim Vortrag im rbb[/caption]
Voice over Voice
Unter dem Begriff Voice over Voice versteht man die audiomäßige Überlagerung eines Originaltons durch einen Sprecher oder Übersetzer. Dabei will man zwar den dokumentarischen Original-Charakter beibehalten, sodass das originale Wort noch hörbar aber nicht mehr störend ist. Ist diese Überlagerung zwischen Original- und Sprecherton audiomäßig allerdings nicht sehr unterschiedlich, so wird eine starke Konzentration auf den Sprecherton erforderlich. Am unangenehmsten ist es, wenn der Originalton in einer fremden Sprache ist, die man eventuell sogar noch etwas beherrscht, weil unser Gehirn dann ständig von einer zur anderen Sprache schaltet und stark abgelenkt wird.
Um eine optimale Differenz zwischen den beiden Audiopegeln zu finden, wurden als erster Arbeitsschritt einige solcher von Zuschauern als störend reklamierten Voice-over-Voice-Passagen aus bestehenden Produktionen herausgesucht und als Grundlage für die weiteren Untersuchungen benutzt. Insbesondere beim Programm der Deutschen Welle werden ja sehr viele deutschsprachige Berichte in die Landessprache oder zumindest Englisch übersetzt und dem original deutschen Ton überlagert. Als Ausgangslage wurden einige solcher Sequenzen mit deutlicher Beeinträchtigung der Sprachverständlichkeit gewählt. Aus diesen Sequenzen wurde dann eine Empfehlung abgeleitet, mit welchem Mischungsverhältnis zwei Sprachspuren gemischt werden sollten, um eine optimale Sprachverständlichkeit des Sprechers gegenüber dem Originalton zu erreichen. Signifikante Teile aus diesem Programm wurden als Sequenz herausgeschnitten und die Pegeldifferenz zwischen dem Original- und dem Sprecherton erst einmal ermittelt.
Da es keine für diesen Einsatzfall geeignete Versuchsmethode gab, um eine optimale Differenz des Mischungsverhältnisses zu ermitteln, wurde eine eigene Methode auf einfachster Basis softwaremäßig erstellt. Dabei offerierte man den Versuchspersonen die simple Möglichkeit, durch Veränderung eines einzelnen Reglers ein für sie gutes Mischverhältnis einzustellen, weil der Off-Sprecher-Pegel nicht verändert werden konnte und das Mischverhältnis nur durch Veränderung des O-Ton-Lautstärkepegels erreicht wurde. Um gleiche Bedingungen im Abhörraum zu schaffen wurde es nötig, eine gemeinsame Grundeinstellung der Lautstärke festzulegen. Als Mittelwert für die Abhörlautstärke ergaben sich 51 dbA. Die Versuche wurden über Kopfhörer durchgeführt, einmal mit einer akustischen Wohnzimmersituation und einmal mit einer Studiosituation. Es wurden Audiosequenzen mit und auch ohne Fernsehbild gewählt, um auch den Einfluss des Fernsehbildes mit zu erfassen. Und es wurde weiterhin noch ein höherer Abhörpegel mit 71 dbA zusätzlich untersucht, um Erkenntnisse zu erhalten, wie er sich auf das Abmischverhältnis auswirkt.
Insgesamt testete man mit 32 Versuchsteilnehmern, davon sechs Frauen. Der Altersdurchschnitt bei den Probanden lag bei knapp 40 Jahren, das individuelle Alter lag zwischen 28 und 60 Jahren. Ältere Personen wurde bei dieser Untersuchung nicht akzeptiert, weil erfahrungsgemäß oberhalb von 60 Jahren eine zwar individuell unterschiedliche aber stärker schwankende und tendenziell mit dem Alter zunehmende Schwerhörigkeit angenommen werden musste, die die Untersuchungen möglicherweise verfälscht hätten. Die Auswertung zeigt die Grafik 1: Auf der horizontalen Achse sind die Testsequenzen und auf der senkrechten Achse der Abstand des O-Tons zum Off-Sprecher in Loudness Units (LU) aufgetragen (der Off-Sprecher liegt bei Null).
[caption align]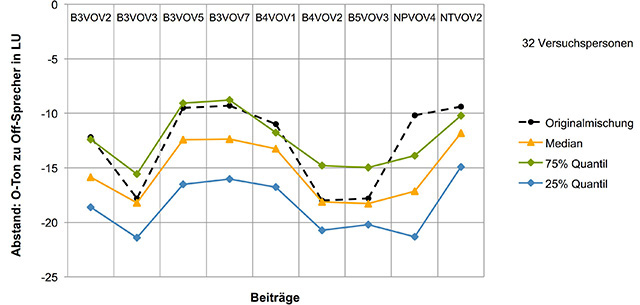 Grafik 1: Hörversuch, Gesamtergebnisse[/caption]
Grafik 1: Hörversuch, Gesamtergebnisse[/caption]
Es zeigt sich erst einmal deutlich, dass für fast jede Sequenz ein anderer Abstand gewählt wurde, d.h. es lässt sich nicht verallgemeinern und ein grundsätzlicher fester Abstand zwischen den beiden Sprachführungen festlegen. Im Zweifelsfalle sollte man die blaue Gruppe als Bezug setzen, denn aus diesem Bereich kamen häufiger Beschwerden, dass der Originalton zu laut dargestellt wird. Beschwerden dass der Originalton zu leise dargestellt wird, sind indessen nicht bekannt.
Zusammenfassend lässt sich feststellen, dass Pegelabstände zwischen den beiden Sprachspuren von 16 bis 23 LU als gut zu bezeichnen sind. Die Abhörlautstärke hat auch einen relativ deutlichen Einfluss (Grafik 2). Die Ergebnisse dieser Untersuchung schlugen sich dann auch in der neuen Sprachverständlichkeits-Guideline von ARD und ZDF nieder, die hier zu finden ist.
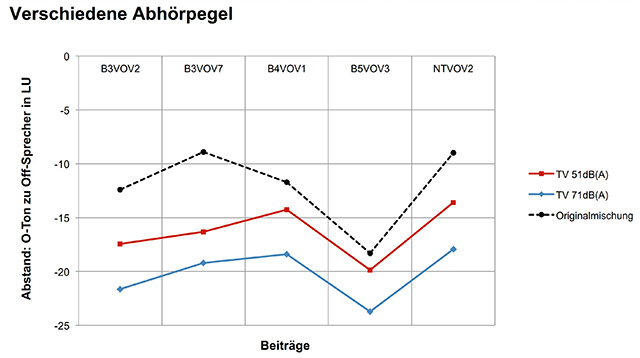 Grafik 2: Verschiedene Abhörpegel[/caption]
Grafik 2: Verschiedene Abhörpegel[/caption]Sprachverständlichkeitsprüfung von Fernsehton
Im zweiten Teil des Vortrags wurde über eine Sprachverständlichkeitsprüfung von Fernsehton berichtet, und zwar gemäß einer Online-Umfrage für Hörgeschädigte. Er fand im Rahmen eines Projekts statt, das sich HBB4All nennt und im Zusammenhang mit dem kommenden HbbTV-Standard 2.0 realisiert wird. Er bietet die Möglichkeit, allen Bürgern einen barrierefreien Zugang zu den Medien zu schaffen. Das im Vortrag beschriebene EU-Projekt mit internationalen Partnern begann im Dezember 2013 und läuft bis zum Dezember 2016 unter dem Begriff „Personalisierbarer Clean Audio Service über IP für hörgeschädigte Benutzer“. Die Online-Umfrage ging über gut ein Jahr. Hier wurden auch die Älteren über 60 Jahre sehr gut abgebildet.
Eine erste Frage galt den Sendungen, bei denen es schwer fällt, die Sprache zu verstehen. Hier lag das Gros der Antworten beim Spielfilm, wobei allerdings zu berücksichtigen ist, dass vorzugsweise Fernsehfilme (zu denen zum Beispiel auch der „Tatort“ zählt) hier unter den Begriff Spielfilm fallen (Grafik 3). Die zweite Frage schlüsselt das Ganze schon auf nach den Ursachen, und hier zeigte sich ganz deutlich, dass die undeutliche Aussprache ganz wesentlich dazu beitrug (Grafik 4). Sie betätigte damit also auch die eingangs vom FKTG-Regionalleiter Wilhelm Sommerhäuser gemachten Anmerkungen zu den Ursachen eines schlechten Fernsehtons. Erst mit deutlichem Abstand an zweiter Stelle wurde das „zu schnelle Sprechen“ genannt. Beides sind Faktoren, die sich im Nachhinein nur noch sehr schwer oder gar nicht ändern lassen. Die erwartete schwierigere Sprachverständlichkeit bei Dialekten und Akzenten war hingegen erstaunlich gering.
 Grafik 3: Online-Umfrage[/caption]
Grafik 3: Online-Umfrage[/caption] Grafik 4: Sprachverständlichkeit[/caption]
Grafik 4: Sprachverständlichkeit[/caption]Als allgemeine Maßnahme zur Verbesserung könnte man eine Anhebung der Stimmfarbe und die Möglichkeit einer eigenständigen Lautstärkeregulierung des Dialogs als wünschenswert betrachten, die in Zukunft zumindest mit den Entwicklungen zum „immersiven Ton“ erreichbar wäre aber wohl doch noch länger auf sich warten lassen dürfte. Es darf bei dieser Auflistung der Prozente allerdings auch nicht verallgemeinert werden, denn die Verteilung der Schwerhörigkeit bei den Umfrageteilnehmern entspricht nicht der Verteilung der deutschen Bevölkerung, die deutlich weniger Hörgeschädigte ausweist. Die Umfrageergebnisse sind im Übrigen umfangreicher auf der Internetseite des Deutschen Schwerhörigenbundes zu finden (mit etwas älterem Zahlenmaterial, aber tendenziell übereinstimmend).
Tonverbesserung für Hörgeschädigte über HbbTV 2.0
Schließlich ging die Referentin noch auf die Möglichkeit ein, den Ton für Hörgeschädigte über HbbTV anzupassen. Bei der neuen Version 2.0 des HbbTV-Standards ist sicherlich eine der wichtigsten Eigenschaften, die Möglichkeit der Synchronisation von IP-Streams mit dem DVB-Stream. Diese synchrone Wiedergabe von zusätzlichen IP-Audio-Streams innerhalb des DVB-Videostreams eröffnet viele Möglichkeiten für AV-Anwendungen, so da sind zum Beispiel Gebärdensprache, Originalton-Umschaltung und Audio-Deskription. Ein Werkzeug, das zurzeit ebenfalls für HbbTV 2.0 entwickelt wird nennt sich „Clean Audio Tool“. Dabei wird versucht, bereits fertige Audiosignale einer Sendung, die über den Fernsehkanal übertragen werden, hinsichtlich ihrer Sprachverständlichkeit aufzubessern, sowohl zur Optimierung des Sprache/Hintergrund-Verhältnisses als auch der Frequenz- und Dynamikanpassung. Hier gab es im Auditorium einige Unklarheiten. Es ging nicht darum, dass der Fernsehschauer den Ton selbst in irgendeiner Weise beeinflussen soll oder kann, sondern, dass ein verbesserter Ton synchron mit dem übertragenen DVB-Fernsehbild über das Internet übertragen und mit einem Smart-HbbTV-Empfänger anstelle des Original-Fernsehtons wiedergegeben wird. Die Synchronisierung selbst ist Teil des neuen Standards und erfolgt praktisch ohne Latenzprobleme durch das Mitsenden von Zeitmarken, die im Smart-Empfänger für die Synchronisation ausgewertet werden. Das geht mit den heutigen Smart-Empfängern mit dem HbbTV-Standard 1 noch nicht.
Für die verbesserte Tonwiedergabe per HbbTV 2.0 sollen verschiedene Bearbeitungsvarianten angeboten werden. Dabei wird zwischen Hörgeräteträgern und Nicht-Hörgeräteträgern unterschieden, sodass jeweils verschiedene Versionen als zwei unterschiedliche Spuren zur Verfügung gestellt werden. Es hat sich nämlich in ersten Tests bereits gezeigt, dass Personen mit Hörhilfe eine Version ohne Frequenz- und Dynamikbearbeitung benötigen bzw. bevorzugen, weil diese Änderungen meist bereits im Hörgerät Berücksichtigung finden. Der Hörgeschädigte mit Hörgerät braucht deshalb meist „nur“ wie natürlich der Nicht-Hörgeschädigte auch noch, eine Anhebung der Sprachlautstärke bzw. Verringerung der nichtsprachlichen Audiosignale.
Was im Prinzip gemacht wird ist eine automatisierte Tonüberarbeitung. Wenn man zum Beispiel ein 5.1-Signal hat, so wird das Center-Signal, das normalerweise ja nur Sprache enthalten soll, als Sprachsignal benutzt, die zwei rechten und linken Signale werden als Stereosignal abgemischt, entsprechend in der Amplitude abgesenkt und wieder mit dem Sprachsignal (Mittensignal) als Stereosignal neu gemischt. Bei einem vorhandenen Stereosignal ist es komplizierter. Hier wird versucht, die Sprache aus dem Gesamtsignal heraus zu analysieren und das Restsignal abzuschwächen damit das Gesamtsignal einen höheren Sprachpegel erreicht.
Hier ist noch einiges an Entwicklungsarbeit zu leisten, aber es gab bereits erste Versuche mit bisher zwei Test-Durchläufen für je zwei Probanden-Gruppen, mit und ohne Hörhilfe. Die Versuche wurden nach ITU-R BS.1284 erstellt und durchgeführt. Dabei wurden Alltagssituationen für Hörversuche nachempfunden, beispielsweise Lautsprecher in einem Raum mit guter Wohnzimmerakustik und ähnlichem. Als Ergebnis kann man zusammenfassen, dass die Sprachverständlichkeit für 5.1-Signale nachweisbar verbessert werden kann, insbesondere dann, wenn die Center-Signale, was sie eigentlich auch sein sollten, frei von Effekten und sonstigen Störgeräuschen sind. Die nächsten Schritte werden neben weiteren Hörversuchen die Festlegung der Mischungsverhältnisse und Varianten für einen ersten Pilotdienst sein.
Lange Diskussionen
Das Thema fand ausgesprochen starke Beachtung, und es wurde zwischen den Teilnehmern im Auditorium und mit der Referentin fast eine weitere Stunde gefachsimpelt, bevor der Berichterstatter als keineswegs letzter den Heimweg antrat.
Ich bin ein normalhörender Fernsehkonsument. Es ist eine bodenlose Frechheit, dass man beim Fernsehen vor lauter Hintergrundgeräuschen keinerlei Sprache mehr verstehen kann ! Vor lauter Aktionwahn ist das wichtigste die Sprache so miserabel geworden, dass es schon an Körperverletzung grenzt, wenn man einen ganz normalen Fernsehabend verbringen möchte.